Horizon Matching
Aligns teacher and student latent trajectories across key denoising stages under compressed step budgets.
Preference-aligned few-step image and video generation without test-time overhead.
University of Science and Technology of China | TeleAI
* Equal contribution
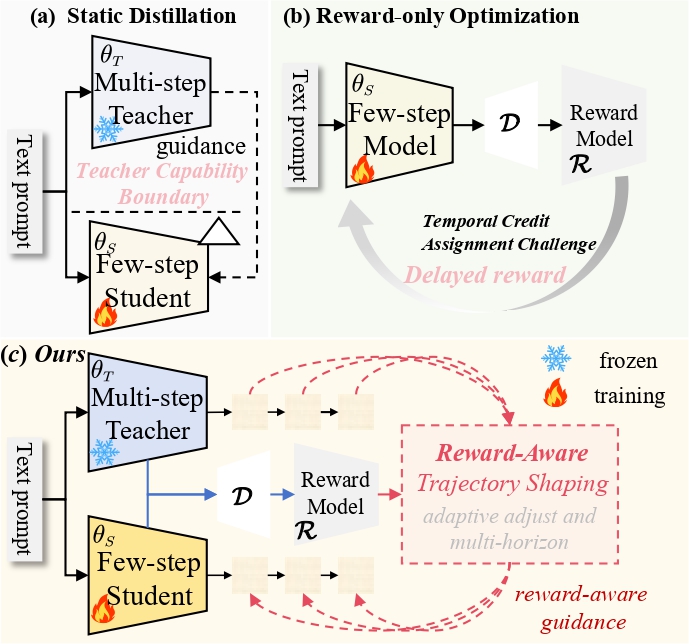
Achieving high-fidelity generation in extremely few sampling steps has long been a central goal of generative modeling. Existing approaches largely rely on distillation-based frameworks to compress the original multi-step denoising process into a few-step generator. However, such methods constrain the student to imitate a stronger multi-step teacher, imposing the teacher as an upper bound on student performance.
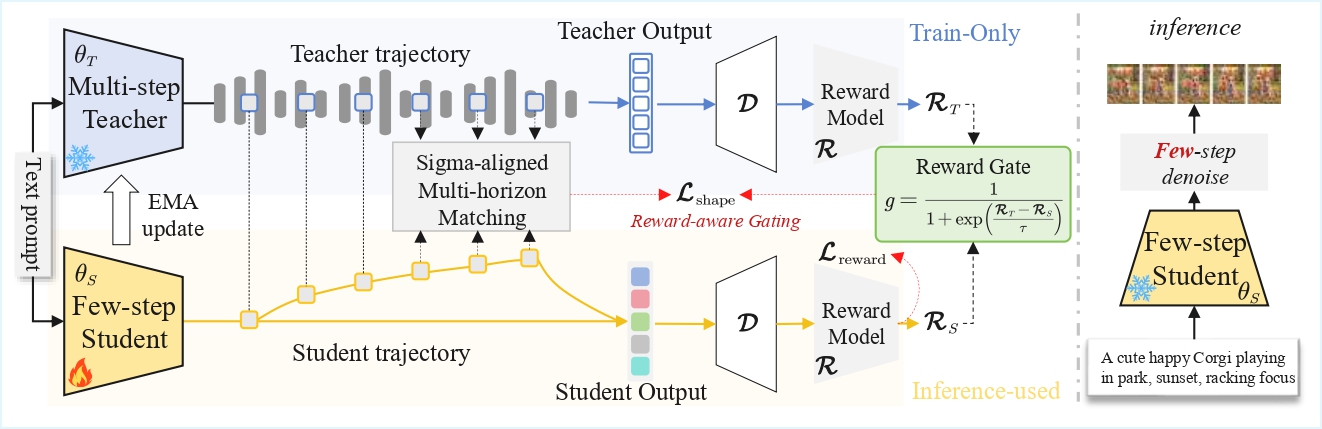
We propose Reward-Aware Trajectory Shaping (RATS), a lightweight framework for preference-aligned few-step generation. Teacher and student latent trajectories are aligned at key denoising stages through horizon matching, while a reward-aware gate adaptively regulates teacher guidance based on relative reward performance. RATS improves the efficiency-quality trade-off in few-step visual generation while preserving the deployment efficiency of the student model.
Aligns teacher and student latent trajectories across key denoising stages under compressed step budgets.
Strengthens teacher guidance when the teacher is more reward-preferred and relaxes it when the student catches up.
Uses the multi-step EMA teacher only during training, adding no computational overhead at test time.
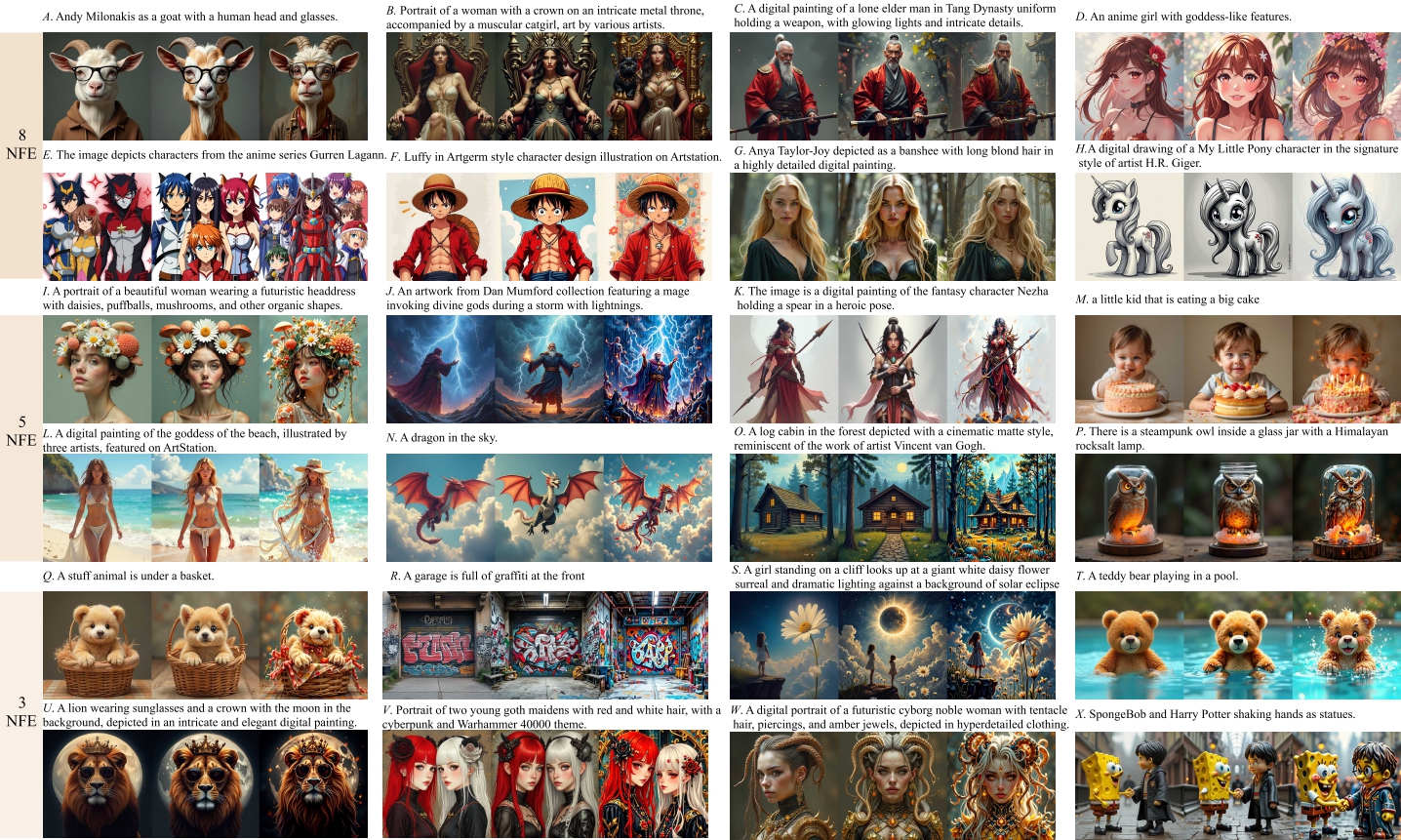
RATS improves FLUX1.0-dev across 3, 5, 8, and 50 NFEs.
| Method | NFEs | HPS ↑ | PickScore ↑ | ImageReward ↑ |
|---|---|---|---|---|
| Baseline | 3 | 18.43 | 19.99 | -0.3551 |
| Ours | 3 | 32.15 +13.72 | 22.46 +2.47 | 1.0956 +1.4506 |
| Baseline | 5 | 26.12 | 21.83 | 0.7443 |
| Ours | 5 | 32.16 +6.04 | 22.68 +0.85 | 1.1337 +0.3894 |
| Baseline | 8 | 28.43 | 22.42 | 0.9140 |
| Ours | 8 | 33.81 +5.38 | 23.14 +0.72 | 1.3240 +0.4100 |
| Baseline | 50 | 29.76 | 22.59 | 1.0037 |
| Ours | 50 | 32.95 +3.19 | 22.79 +0.20 | 1.1544 +0.1507 |
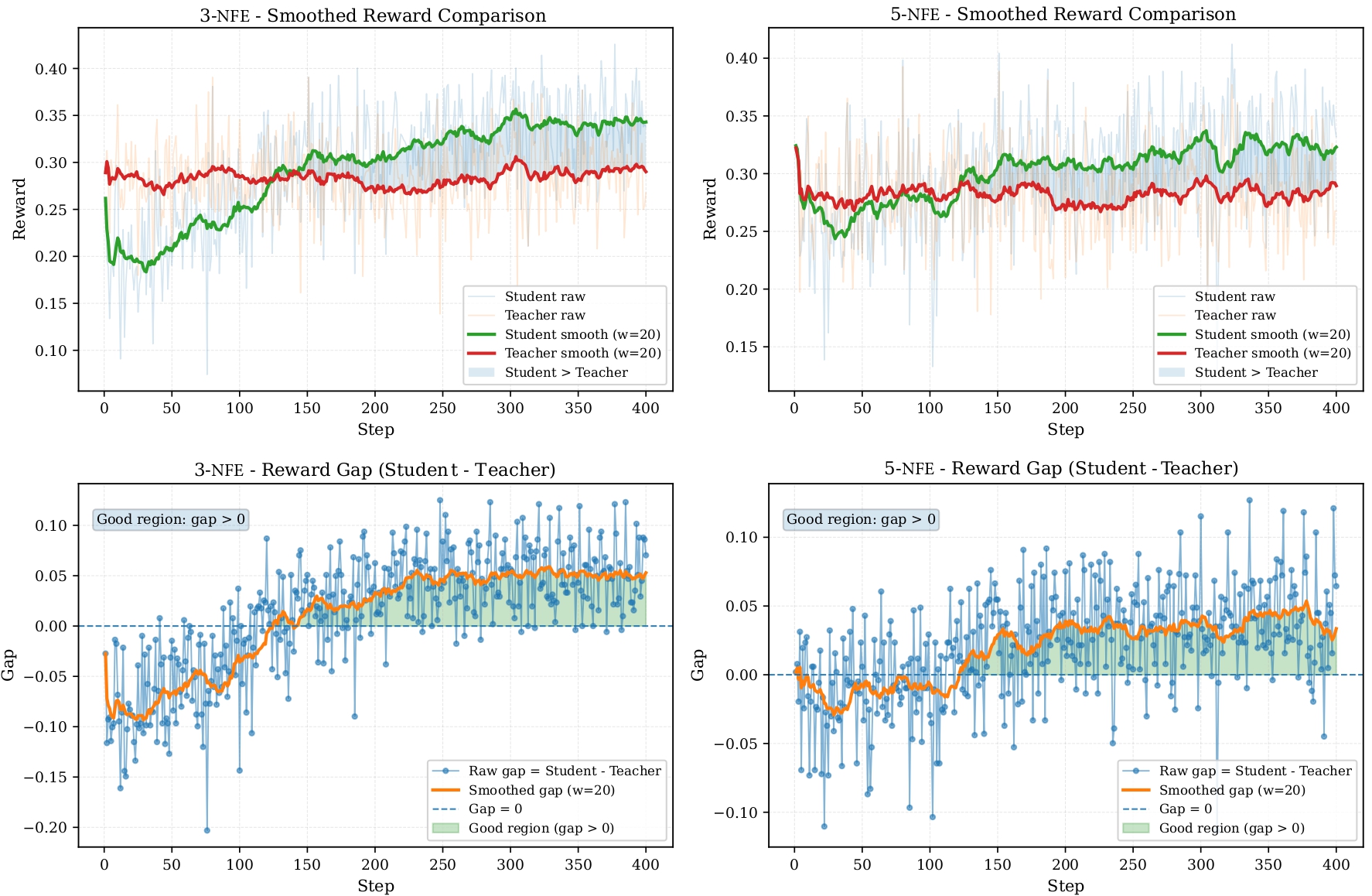
RATS achieves the best HPS and PickScore across all evaluated NFE settings.
| Method | NFEs | HPS ↑ | PickScore ↑ | ImageReward ↑ |
|---|---|---|---|---|
| Flux | 3 | 18.43 | 19.99 | -0.3551 |
| Hyper-SD | 3 | 28.80 | 22.14 | 0.9882 |
| SenseFlow | 3 | 30.63 | 22.33 | 1.2030 |
| Ours | 3 | 32.15 | 22.46 | 1.0956 |
| Flux | 5 | 26.12 | 21.83 | 0.7443 |
| Hyper-SD | 5 | 27.83 | 22.08 | 1.0710 |
| SenseFlow | 5 | 30.99 | 22.53 | 1.2110 |
| Ours | 5 | 32.16 | 22.68 | 1.3337 |
| Flux | 8 | 28.43 | 22.42 | 0.9140 |
| Hyper-SD | 8 | 30.50 | 22.76 | 1.0410 |
| SenseFlow | 8 | 30.99 | 22.59 | 1.1720 |
| Ours | 8 | 33.81 | 23.14 | 1.3240 |
| Flux | 50 | 29.76 | 22.59 | 1.0037 |
| Hyper-SD | 50 | 30.01 | 22.51 | 0.9461 |
| SenseFlow | 50 | 30.69 | 22.31 | 1.0810 |
| Ours | 50 | 32.95 | 22.79 | 1.1544 |
The largest improvements appear in the low-step video generation regime.
| Method | NFEs | Quality Score ↑ | Semantic Score ↑ | Total Score ↑ |
|---|---|---|---|---|
| Wan | 50 | 83.08 | 62.93 | 79.05 |
| Ours | 50 | 83.99 +0.91 | 65.99 +3.06 | 80.40 +1.35 |
| Wan | 8 | 77.82 | 48.74 | 72.01 |
| Ours | 8 | 82.66 +4.84 | 70.35 +21.61 | 80.20 +8.19 |
| Wan | 5 | 73.64 | 34.10 | 65.73 |
| Ours | 5 | 81.23 +7.59 | 67.78 +33.68 | 78.53 +12.80 |
RATS combines few-step generation and preference alignment with substantially lower total training time.
| Method | Step Time (s) | Peak Memory (GB) | Per-Step Compute (TFLOPs) | Total Steps (K) | Total Time (h) | Extra Data | Few-Step | Preference Align |
|---|---|---|---|---|---|---|---|---|
| SenseFlow | 7.31 | 78.87 | 801.28 | 12.0 | 24.35 | Yes | Yes | No |
| DanceGRPO | 212.71 | 34.05 | 1605.00 | 0.2 | 11.78 | No | No | Yes |
| Ours | 7.57 | 67.67 | 1229.60 | 0.4 | 0.83 | No | Yes | Yes |
Experiments show that RATS consistently improves the efficiency-quality frontier, narrowing the gap between few-step students and stronger multi-step generators for both image and video generation.

@article{li2026rats,
title = {Reward-Aware Trajectory Shaping for Few-step Visual Generation},
author = {Li, Rui and Li, Bingyu and Liang, Yuanzhi and Huang, Haibin and Zhang, Chi and Li, XueLong},
journal = {arXiv preprint arXiv:2604.14910},
year = {2026}
}